May | 2020
With advancements in Artificial Intelligence and Machine Learning techniques, organizations across the globe have realized the potential of AI in enabling quick and informed decisions. They are moving towards rapid adoption of these technologies for survival and subsequent favorable outcomes. Due to this growing demand for AI across industries, infrastructure decisions are increasingly being based on this workload.
However, before deciding the infrastructure solution for AI platforms, enterprises should gain insight into the data lifecycle from an AI model’s perspective. Data can be the key challenge for implementation of AI and ML.
Here are some key pointers that enterprises need to know about data before defining infrastructure for AI:
Efficient management of data for enabling AI
Data is crucial for modern AI and ML algorithms. Collection of data in raw format, managing these big chunks of datasets, and labeling them with related information to help train an AI model are the major data challenges.
A data architecture that describes how data is collected, stored, transformed, distributed and consumed is essential to implement AI solutions.
Datasets have to go through multiple processing stages before being used to train the AI model. Let’s see what happens to data at each of these stages.
Data Collection and Ingestion - This step involves storing data from multiple sources into a data lake. The data here is a mix of structured and unstructured data. The data lake needs to be scalable and agile to handle every type of data. The datasets will have Inferences, which must be saved to be processed in the further steps.
Data Preparation (Clean and Transform) - Data stored in data lake post ingestion isn’t suitable for utilization in training AI models as it needs cleansing and required transformations. Thus, transformations are performed in data lakes.
Explore - Next step is to feed these processed datasets from data lake to the AI/ML tools in the AI based platform, which possesses high storage with GPU and CPU servers. Initially this platform conducts testing with a smaller set of data and then full-scale model training is enabled through multiple iterations.
Training & Evaluation - At this stage, random data sets are taken from data lake and fed into the AI platform for training and updating the model. Infrastructure requirement at this stage is to have high performance storage to compete with high processing speed of GPUs.
Scoring or Prediction - After training and evaluation of AI models, they are circulated in production as PMML (Java) file, model objects (Python flask, RServer, R modelObj) for prediction (scoring). The business application needing prediction invokes the objects in accordance with the algorithm.
After completion of data processing and training of models, the data becomes redundant or cold and is no longer needed. But sometimes, the cold data may be needed to refer back for problem-solving. Hence, cold data is mostly stored in a low-cost storage area.
Infrastructure selection criteria for AI
To make the right choices about compute and storage, it is vital to understand the requirements of storage and compute at multiple stages of the data lifecycle.Figure 1 maps the storage and compute requirements with the phases of data lifespan. However, this might vary on a case-to-case basis.
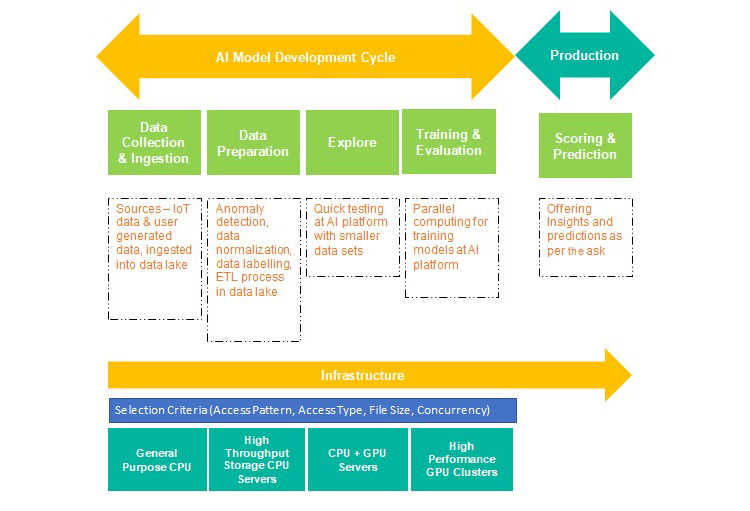
Figure 1: Infrastructure storage and compute requirements during data lifespan phases
Storage selection criteria
In case of standardized and small scale ML requirements, one can go ahead with scaled out shared storage across all phases. For large scale ML requirements which also involves deep learning, throughput differs radically throughout different stages and hence separate fit for storage becomes a better and cheaper solution as compared to having a solitary shared storage.
Compute selection criteria
The requirements for compute performance depends on the phase of data lifespan and inclusion of deep learning. Depending on the usage and storage advances, the data lake deployment can be on discrete servers or servers with storage. In discrete servers, single server provides storage plus computation, while in the latter, a committed storage box offers storage and servers provide compute.
Public cloud selection
Public cloud acts as an alternative to on-premise structures as they offer key features that are quicker and easier to leverage. These include scalability, agility and hybrid usage of infrastructure. Moreover, public cloud offers readily accessible data lakes, thereby reducing overhead costs.
However, the choice between public cloud and on-premise structure is dependent on additional factors like setup size, business needs, landscape of applications etc.
Container platform
Container platform helps on-premise structures to achieve the functionalities of public cloud. With the help of containers and server-less computing (quickly scalable), ML models are able to act independently, hence being more cost-effective with less overheads.
On-premise containers can be deployed as a platform. But, the methodology, compatibility, and AI platform and ML tools used need to be confirmed.
Various AI applications / use cases like language translation, face detection, financial risk stratification, route planning and optimization, dynamic pricing and autonomous driving have come up but there is one common feature that drives them all – their dependence on hardware. All these applications have different compute requirements that result in varied chip compatibility. Factors like processing speed, hardware interfaces, flexibility, backward compatibility, need for technical capabilities decide the type of chip that is needed per application. For e.g. for a face detection use case, the possible AI chips for training phase could be a GPU or FPGA (Field-programmable Gate Array), whereas inferences can be achieved with the help of CPU or an ASIC (Application specific integrated Circuits) chip.
Right infrastructure matters
AI is the next wave of digital disruption - the global business value derived from AI would be huge with its impact felt across the value chain. Enterprises need to figure out the infrastructure that facilitates AI and ML to leverage its potential. The high performance workload in today’s era requires modern infrastructure that can provide better performance, scalability and agility at a lesser cost.
Raju Singh Mahala
Raju Singh Mahala is a Sr. Architect at Data Center & Cloud Practice in Cloud and Infrastructure Services at Wipro. He has more than 20 years of experience in the IT industry across IT Infrastructure Solution Design, Consulting, Support & Services, IT Strategy & Management and Pre-Sales.
Siddharth Rawat
Siddharth is a Consultant for Strategy & Planning function in Data, Analytics, and AI service line at Wipro.
His areas of expertise include analytics and AI, and helps drive cohesive strategies with market insights, competitive landscape and related ecosystems.
Anil Kumar Damara
Anil Kumar Damara heads the Data, Analytics, and AI Strategy group at Wipro. He has over 16 years of experience, most of it in Data, Analytics and AI ecosystem. His core skills include strategic consulting, strategy execution, and digital strategy and operations.